RAG 还是 MCP?每个 AI 开发者真正需要知道的
- 1. RAG 到底是什么(以及它不是什么)
- 2. 管道实际如何工作
- 3. RAG 真正适合的场景
- 4. RAG 做不到的事
- 5. MCP 到底是什么
- 6. MCP 如何工作
- 7. MCP 是正确选择的场景
- 8. 大多数文章对 MCP 说错了什么
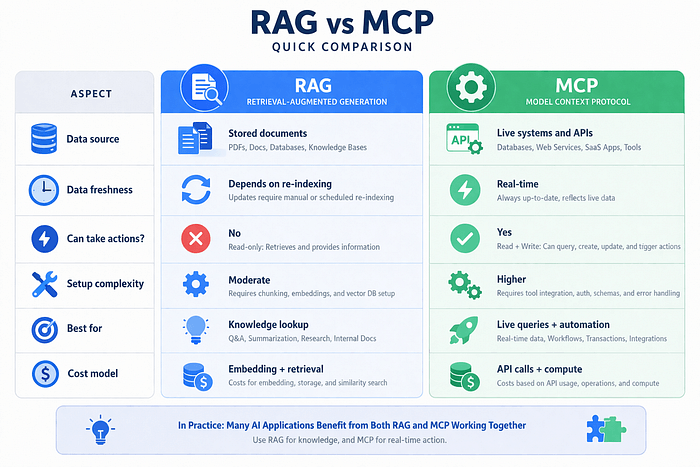
- 9. RAG vs MCP:直接对比
- 10. 实际该什么时候用哪个
- 11. 大多数团队实际使用的架构
- 12. 大多数文章漏掉的一些事
- 13. 总结
你可能用 LLM 做过项目,然后遇到那个时刻——模型突然就不按你预期的方式工作了。模型很聪明,推理清晰,写代码也很棒,能毫不费力地分解复杂问题。但现实很快给了你一耳光:它不知道上周二发生了什么。它访问不了你的内部文档。它不知道客户的订单状态,也不知道你的数据库里现在有什么。
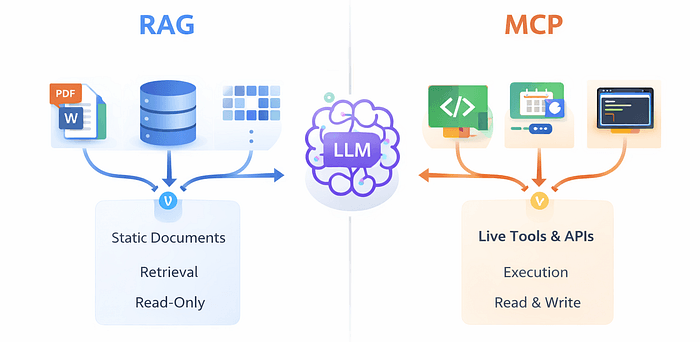
这不是能力问题,这是上下文问题。解决这个问题有两种主流方案:RAG 和 MCP。而大多数人解释它们的方式,会让你觉得它们是竞争关系——其实不是。它们解决的问题完全不同。
但首先,让我们真正理解每一种是做什么的。我在多个项目中都接触过这两种模式,我不断看到的困惑不是技术本身,而是什么时候该用哪个。读完这篇文章,你应该就清楚了。
1. RAG 到底是什么(以及它不是什么)
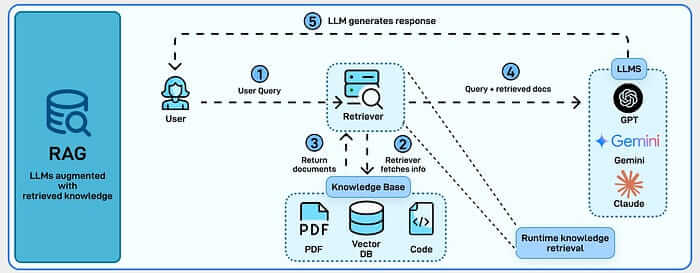
RAG 代表检索增强生成(Retrieval-Augmented Generation)。抛开术语,它做的事情是:不依赖模型训练时学到的知识,而是在查询时从你自己的文档中提取相关内容,作为上下文交给模型。
把它想象成给 AI 配了一个组织良好的图书馆,外加一个搜索引擎。
当用户提问时,系统不会凭记忆猜测。它搜索你的文档库,拉取最相关的片段,和问题一起塞进提示词。模型然后基于这些新检索到的上下文来回答,而不是依赖陈旧的训练权重。
2. 管道实际如何工作
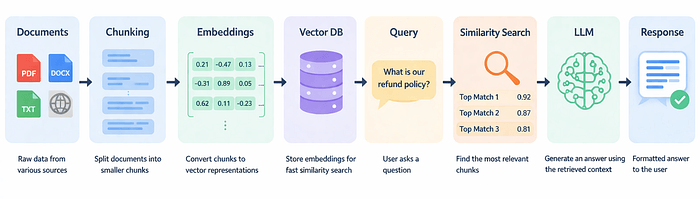
以下是底层发生的事:
你摄入文档——无论是 PDF、内部 Wiki、支持手册、合规策略、产品规格,任何基于文本的内容。这些文档被切分成块(chunks)。块的大小比大多数教程告诉你的要重要得多。每个块通过 embedding 模型转换为向量嵌入,存储在向量数据库中(Pinecone、Weaviate、pgvector、ChromaDB,任选)。当用户发送查询时,该查询也被 embedding,系统运行相似度搜索找到最匹配的块。这些 top-k 块随原问题一起发给 LLM。LLM 基于检索到的上下文生成回复。
就这些。概念上出奇地简单,实践中真正做好却很难。块大小、重叠、embedding 模型选择、检索策略、重排序——可调的旋钮非常多。
3. RAG 真正适合的场景
RAG 是以下场景的正确选择:
- 基于产品文档的客服机器人
- 面向 HR 或法务团队的内部知识助手
- 代码库或 API 文档的技术问答
- 策略查询工具
- 学术和研究参考文献系统
任何你需要用户用自然语言查询文本库的地方,RAG 都是你的朋友。
4. RAG 做不到的事
说实话:RAG 只能在你已存储的内容上工作。它不能实时获取任何东西。它不能更新记录、不能触发工作流、不能告诉别人当前股价是多少。而且如果你的文档最近没有重新索引,答案可能是过时的。
RAG 给了 AI 长期记忆。但仅有记忆不足以让 AI 采取行动。
5. MCP 到底是什么
MCP 代表模型上下文协议(Model Context Protocol)。它是一个较新的模式,老实说这个名字并不能帮助解释它是做什么的。所以这是直白版:MCP 是 AI 模型连接到实时系统并实时使用它们的标准化方式。
如果 RAG 是图书馆,MCP 就是智能手机。模型可以检查实时数据、调用 API、更新记录、发送消息、触发工作流。它可以做事情,而不仅仅是回忆事情。
6. MCP 如何工作
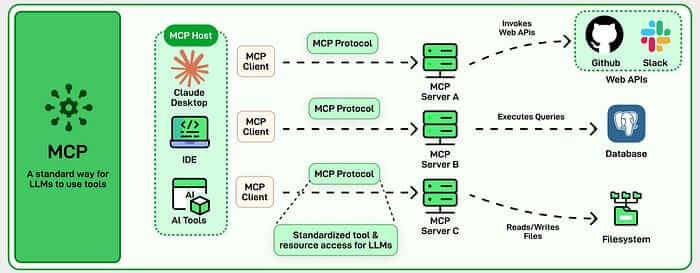
你定义 AI 可以访问的工具。这些可以是内部 API、数据库、CRM 系统、外部服务——任何有接口的东西。你设置权限:模型对每个工具可以做和不可以做什么。当用户提问时,LLM 推理该调用哪个工具,调用它,获取结果,然后基于最新数据构建回复。动作可以链式进行——检查库存 → 确认订单 → 通知发货团队 → 记录到 CRM。一个用户请求,多个系统调用。
关键区别:MCP 不是关于检索已存储的内容。它是关于在问题提出的那一刻与实时系统交互。
7. MCP 是正确选择的场景
实时订单跟踪。在给客户报价前检查库存。拉取当前财务数据。搜索实时 CRM 获取账户历史。作为工作流的一部分发送 Slack 通知或创建 Jira 工单。任何数据频繁变化、且操作需要立即执行的场景。
8. 大多数文章对 MCP 说错了什么
人们经常低估复杂度。MCP 比 RAG 更难实现。你需要集成。你需要仔细考虑安全性,特别是模型被允许写入 vs 仅读取的权限。工具可用性和可靠性成为系统可靠性的组成部分。如果 API 挂了,AI 就无法回答。
话虽如此,回报是真实的。一个拥有 MCP 访问权限的模型不再只是一个知识检索器,而开始成为一个真正的智能体。
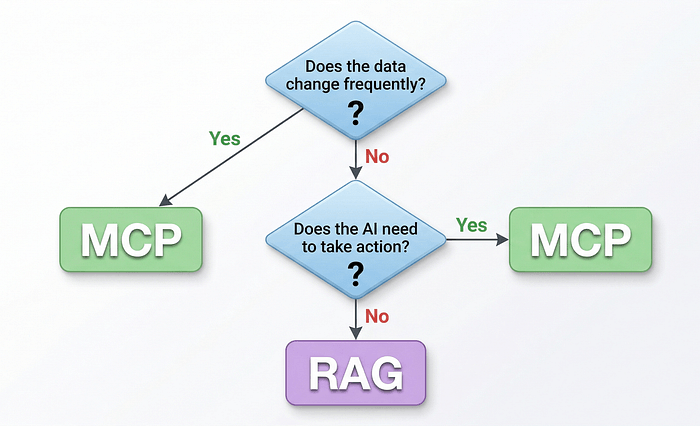
9. RAG vs MCP:直接对比
10. 实际该什么时候用哪个
让我直说,因为很多「X 场景用 Y」的指南太模糊了,没什么用。
10.1 选 RAG 当:
- 你的用户需要从特定文档库获得答案
- 数据一天之内变化不超过一次
- 你想要更低的运营成本和更简单的基础设施
- 用例本质上就是「帮我查一下这个」
10.2 选 MCP 当:
- 答案取决于不断变化的数据
- 用户的目标需要 AI 在系统中实际执行操作
- 你在构建工作流自动化,而不是问答工具
- API 调用的延迟是可接受的
10.3 当你在构建任何严肃的东西时,两者都用
实际上,划掉上面那句——两者并用已经不是什么特殊场景了。它正在成为生产级 AI 应用的默认架构。图书馆和智能手机。静态知识和实时访问。读和写。
大多数真正的企业 AI 助手需要两者兼备,因为用户在同一个会话中会问跨越文档和实时系统状态的问题。
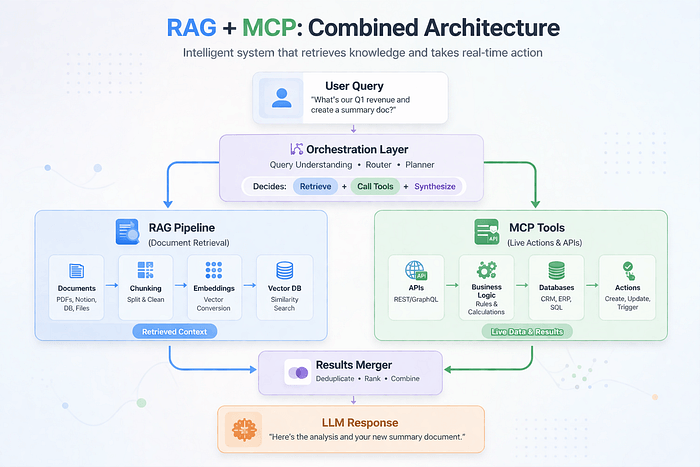
11. 大多数团队实际使用的架构
以下是 RAG + MCP 组合系统在实践中的样子:
用户问:「我们超过 200 美元的订单退货政策是什么,另外你能查一下订单 #7821 是否符合条件吗?」
第一部分是 RAG 查询——从文档库中拉取退货政策。第二部分是 MCP 调用——在订单管理系统中实时查询订单 #7821。模型处理两者,串联结果,给出一个连贯的答案。两种方法单独来看都无法处理这个需求。合在一起,它们让 AI 对真正的业务工作流真正有用。
12. 大多数文章漏掉的一些事
12.1 分块策略比人们承认的更重要
在 RAG 中,你如何分割文档会极大影响检索质量。固定大小分块是懒惰的默认做法。语义分块——在自然主题边界处切分——能带来实质性的更好的结果。大多数教程跳过了这一点。
12.2 MCP 需要一个信任模型
当你的 AI 可以写入系统而不仅仅是读取时,你需要认真考虑在不经过人工批准的情况下它被允许做什么。写入权限、不可逆操作的确认步骤、审计日志——这些在生产中不是可选项。
12.3 重排序是 RAG 的秘密武器
很多 RAG 实现在向量相似度搜索后就止步了。添加一个交叉编码器重排序器作为第二轮处理,能显著提升答案质量。这是一个值得了解的多余步骤。
12.4 延迟特征完全不同
从本地向量存储进行 RAG 检索可以在毫秒级完成。MCP 调用外部 API 可能需要几秒钟。如果你在结合使用两者,你的用户体验需要考虑这个差异——流式响应在这里很有帮助。
13. 总结
RAG 给你的 AI 知识。MCP 给你的 AI 实时访问和行动能力。它们不是竞争模式。它们作用于 AI 应用需要做的不同层面。一个处理记忆,一个处理行动能力。
大多数严肃的 AI 应用最终两者都需要。而理解它们之间的区别,正是能把能构建有用 AI 系统的工程师和只会写提示词的人区分开的东西。
本文的 Part 2 将从零开始介绍如何构建一个生产级 RAG 管道——分块策略、embedding 模型选择、检索调优,以及大多数实现悄悄失败的地方。关注我,不要错过。