如何用 AI 精准提取文档中的所有内容
TL;DR:文档解析器在处理真实世界中常见的复杂布局时表现不佳——比如带有合并单元格的表格、跨页断行、错位文本。此外,大量信息存在于图表或插图中,需要精确提取。本文带你一步步构建一个简单的解析器,能从文档中提取所有多模态数据,并精确保留布局。它作为一个可复用的 Python 包,支持多种模型提供商。
文档内容的精确提取对 AI 应用至关重要。例如,在用 AI 处理采购订单以生成销售草稿时,AI 智能体或 LLM 首先需要准确理解采购订单的内容和精确布局。一个错位的表头会让 LLM 读错数量,导致价格计算错误。同样,因表格跨页断行而漏掉一行明细,会导致 LLM 完全跳过某个产品。
在我们自己的生成式 AI 项目(GAIK)中,这类问题经常出现——我们用这个开源工具包处理企业文档。许多客户文档,如采购订单或物料清单,都可能包含混乱的表格。
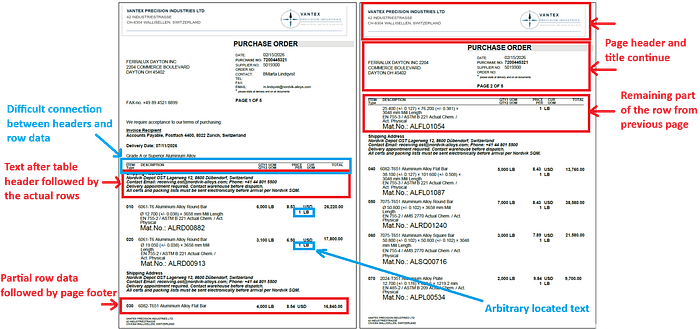
举个例子:下面是一份采购订单的两页(出于隐私考虑修改了内容,但保留了布局)。表头和行数据之间有一段文字。当然,这不是放置这段文字的正确位置,它本应放在表格之前或之后的其他位置。但在客户文档中遇到这种结构是相当常见的。这段文字还在表内其他地方不必要地重复出现。表格跨越多页,行数据部分地分散在不同页面上。例如,第一页包含了第三个物料(030)的部分数据,接着是表脚,然后下一页是重复的页头和标题。
专门的解析器——如 PyMuPDF、PyMuPDF4LLM 或 Docling——无法准确提取这个表格结构。

我在以下文章中解决了这个问题:
How to Extract Everything from Documents Using AI——我创建了一个视觉增强的文档解析器和 RAG 分块器。
Building a Generic Knowledge Extraction AI Framework for Organization-Specific Use Cases——让非技术用户用自然语言指定需求,自动生成模式并提取数据。
即使是这两个解析器也无法正确提取这种混乱的表格布局。以下是 Docling+LLM 解析器和 GAIK 的 Vision+ 解析器的提取结果:
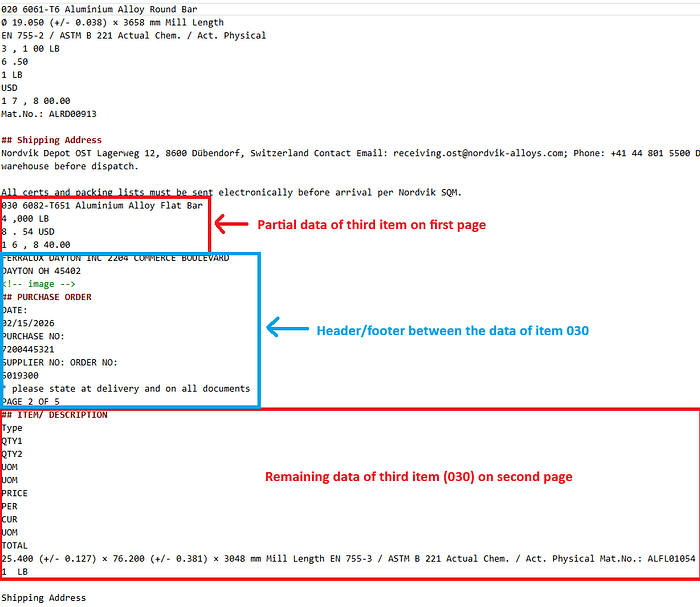
最终的修复方案其实比我想象的简单得多。关键在于使用正确的提示词。只是换了一种方式告诉 AI 模型你想要什么。
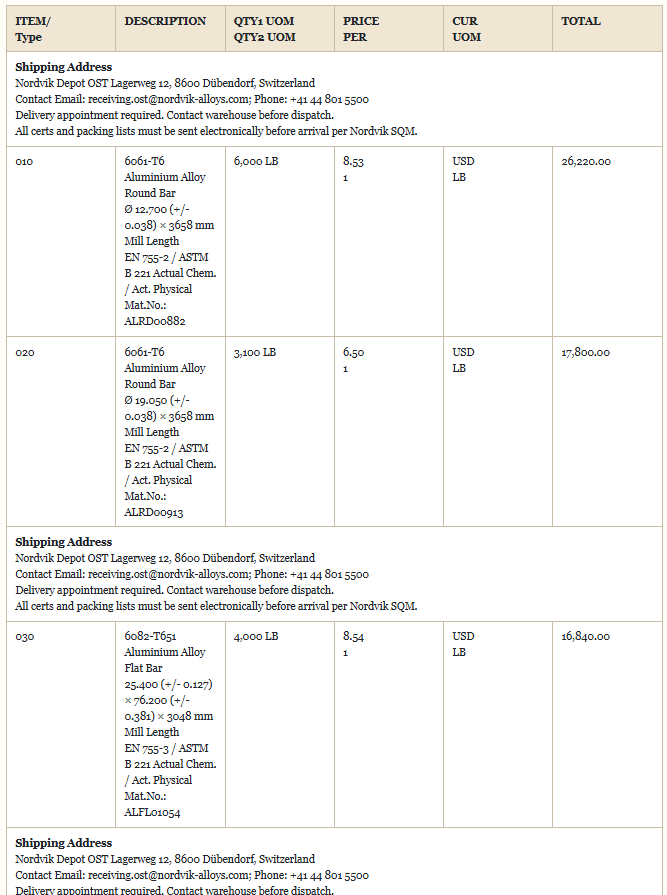
本月初,LlamaIndex 发布了他们在基准测试中使用的文档解析提示词,这些提示词改变了一切。下面是证据——同一份采购订单,之前所有解析器都失败的那份,用新的方法成功提取了:

在本文中,我们将创建一个多模态解析器,从具有混乱布局的文档中精确提取/解析内容。
1. 关键在于一些特定的提示词
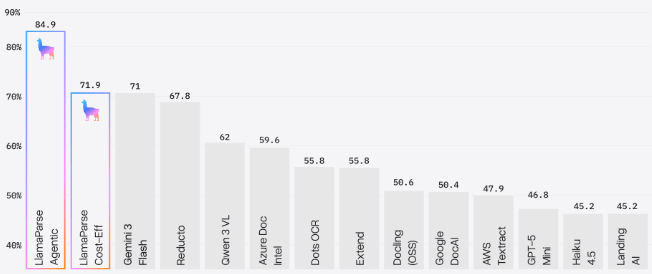
本月初,LlamaIndex 发布了一个开源框架(ParseBench),用于基准测试文档解析器将 PDF 转换为 AI 智能体可用输出的能力。他们测试了 14 种不同的方法:通用视觉 LLM、专门的解析器,以及他们自己的 LlamaParse。基准测试结果发表在这项研究中:
ParseBench: A Document Parsing Benchmark for AI Agents——AI 智能体正在改变文档解析的要求。重要的是语义正确性:解析后的输出必须让 AI 能理解和使用。
结果表明确实如此:智能体解析(如 LlamaParse)和基于 LLM 的解析(如 Gemini 3 Flash)优于专门的文档解析器。
我很好奇他们是如何让基于 LLM 的解析工作得这么好的。于是我去读了实际的研究论文。我本以为会看到一些巧妙的架构技巧——微调模型,或带有验证循环的多步骤管道。结果我却发现了一些特定的提示词。那些我们从没想过要用的提示词。
1.1 这些提示词有什么特别之处?
当你让 LLM 以 Markdown 格式输出表格时(这是大多数解析器的默认做法),它无法正确保留合并单元格和多级表头的布局。例如,一个带有两行表头、跨多列的采购订单,会变成扁平且含义模糊的形式。
LlamaIndex 提出的提示词使用 HTML 的 colspan 和 rowspan 属性来提取表格,从而编码完整的结构。提示词要求 LLM 将表格转换为 HTML 格式(<table>、<tr>、<th>、<td>),并使用 colspan 和 rowspan 属性保留合并单元格和层级表头。
同样,对于图表,LLM 被要求将它们转换为表格,使用扁平组合列头,使每个数据单元格的行包含所有标签。
以下是 LlamaParse 为 OpenAI 和 Claude 模型提议的系统提示词和用户提示词:
OPENAI_CLAUDE_SYSTEM_PROMPT = """You are a document parser. Your task is to convert document PDFs into clean, well-structured Markdown.
Guidelines:
- Preserve the document structure, including headings, paragraphs, lists, and tables.
- Convert tables to HTML using `<table>`, `<tr>`, `<th>`, and `<td>`.
- For existing tables in the document, use `colspan` and `rowspan` attributes to preserve merged cells and hierarchical headers.
- For charts or graphs converted into tables, use flat combined column headers.
- Describe images and figures briefly in square brackets.
- Preserve any code blocks with appropriate syntax highlighting.
- Maintain reading order: left to right, top to bottom for Western documents.
- Do not add commentary or explanations. Output only the parsed content.
Additionally, wrap each layout element in a `<div>` tag with:
- `data-bbox="[x1, y1, x2, y2]"` for the bounding box in normalized 0-1000 coordinates
- `data-label="<category>"` where category is one of: `Caption`, `Footnote`, `Formula`, `List-item`, `Page-footer`, `Page-header`, `Picture`, `Section-header`, `Table`, `Text`, `Title`.
Place elements in reading order. Every piece of content must be inside exactly one `<div>` wrapper."""
对于 Google 的 Gemini 模型,提示词基本相同,只是 data-bbox 的坐标顺序改为 [y_min, x_min, y_max, x_max],以匹配 Gemini 模型的原生输出格式。
不是用 Markdown 表格(无法准确表示合并单元格和混乱的现实表格),提示词要求的是带 colspan 和 rowspan 的 HTML 表格。每个布局元素都有归一化坐标的边界框。这意味着下游代码可以重建页面的空间布局,而无需依赖原始 PDF 渲染器。
2. 用于精确解析的多模态解析器
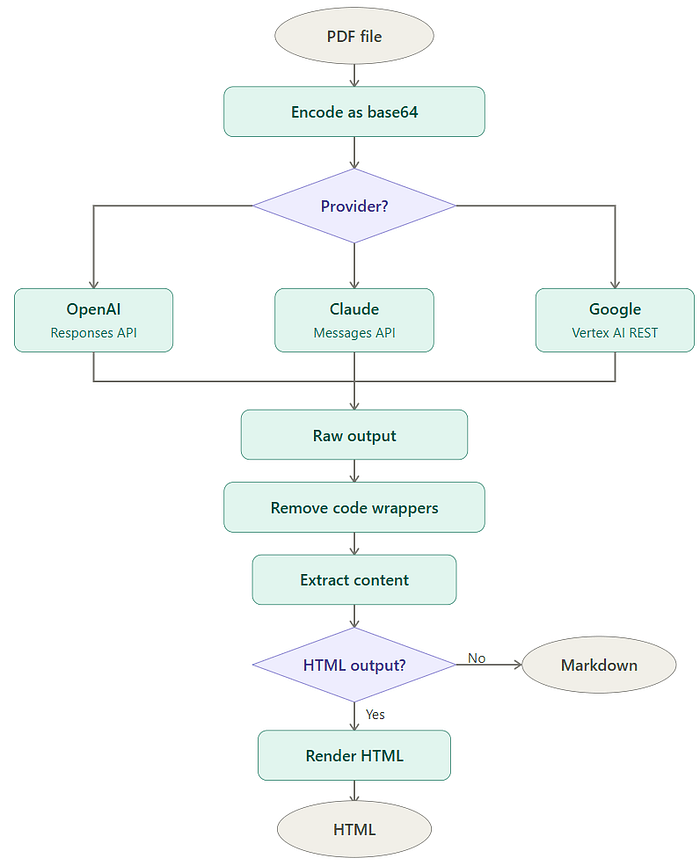
我将使用上述提示词的解析管道打包成了一个 Python 类,它读取 PDF 文档,让用户选择提供商和模型(OpenAI、Anthropic 或 Google),并附带多个其他选项。
完整代码在 GitHub 仓库中。MultimodalParser 类只有一个方法 parse(),它编排了整个管道。
parser = MultimodalParser(
model_provider="google",
model="gemini-3.1-flash-lite-preview",
reasoning_effort="low",
merge_table=True,
create_html=True,
)
result = parser.parse("document.pdf")
几个值得理解的参数:
reasoning_effort——模型的思考预算:"low"、"medium"或"high"。更高的努力可以提高复杂布局的准确性,但更慢、更贵。merge_table——为True时,向用户提示词追加指令,告诉模型合并跨页的表格。additional_instructions——追加到用户提示词中的额外指令,用于特定领域的规则。create_html——为True时,将清洗后的 Markdown 渲染为 HTML 文档。
parse() 方法首先以原始字节读取 PDF,编码为 base64 字符串,以便嵌入 JSON API 负载并发送给选定的 LLM。然后根据选定的提供商构建正确的消息结构——因为 OpenAI、Claude 和 Google 各自期望不同的内容格式。
LLM API 调用后,模型返回其原始响应,这是 Markdown 文本和包含边界框坐标的 <div> 包装器的组合。一个清理过程移除模型可能包裹输出的代码块围栏。另一个方法从这些 <div> 包装器中提取实际内容,生成干净的 Markdown。如果设置了 create_html=True,干净的 Markdown 会转换为带样式的 HTML 文档。
3. 如何使用
多模态解析器已被创建为 GAIK 项目开源生成式 AI 工具包的一个可复用软件组件。可以作为独立的 Python 包安装:
pip install "gaik[multimodal-parser]"
以下是一个最小示例,使用 gemini-3.1-flash-lite-preview 和低推理努力来解析同一份采购订单。此示例将解析输出保存为原始 Markdown、干净 Markdown 和 HTML 格式。
from pathlib import Path
from dotenv import load_dotenv
from gaik.software_components.parsers.multimodal_parser import MultimodalParser
load_dotenv()
OUTPUT_DIR = Path(__file__).parent / "output"
parser = MultimodalParser(
model_provider="openai",
model="gpt-5.4-mini",
reasoning_effort="low",
merge_table=True,
create_html=True,
)
result = parser.parse("sample_PO.pdf")
# 输出保存为 raw_markdown, clean_markdown, html
同一份采购订单的正确合并和结构化输出(HTML 格式)如上所示。
4. 观察与总结
即使是较小的模型,如 gemini-3.1-flash-lite-preview 和 gpt-5.4-mini,在 reasoning_effort 设为 low 的情况下,也能准确提取混乱的采购订单。关键在于使用正确的提示词。
需要注意的是,这种解析在准确性比速度更重要、不需要快速或实时响应的场景下非常有用。例如,在采购订单处理中,准确的解析以确保精确的价格计算比速度更重要。
提高推理努力会大幅增加处理时间和成本。更大的模型(如 gpt-5.4,reasoning_effort 设为 high)会变得非常慢。因此,high 推理努力,特别是对于大模型,应仅在文档布局极其复杂时使用。
在成本和速度方面,gemini-3.1-flash-lite-preview 是最佳选择。
additional_instructions 参数可用于提供用例特定的解析指令。例如,对于法律文档,可以设置为「精确保留脚注编号,与源文档完全一致」。
我很想知道你遇到了哪些文档解析问题。这些方法能解决你的问题吗?