在 Claude Code 里养一个"高级工程师"团队:Sub-Agent 架构实战
- 1. 不是”更快的打字员”,而是”懂流程的架构师”
- 2. 团队代码库:三层架构
- 3. 头脑风暴与设计:写代码前的硬门禁
- 4. 执行引擎:Sub-Agent 驱动的开发
- 5. TDD 铁律与系统化调试
- 6. 写技能 = 对流程文档做 TDD
- 7. 真实效果:测试一个完整项目
- 8. 如何进一步改进
- 9. 总结
1. 不是”更快的打字员”,而是”懂流程的架构师”
Junior 和 Senior 工程师之间真正的差距,不是语法熟练度,而是在压力下依然保持的预测能力、风险管理和工程纪律。
AI Agent 正好缺这个:它们会跳过审查、给自己找捷径、产出”自己觉得很好但没人审过”的代码。Anthropic 的实验已经证明,多个 Agent 协作时如果没有结构化流程,更多的 Agent 只会带来更多的混乱和浪费的算力。
FareedKhan 最近开源了一个项目,用 Claude Code 的 Sub-Agent 系统搭建了一套完整的”Staff Engineer 团队”,从设计到发布,每个环节都有专人(Agent)把关:
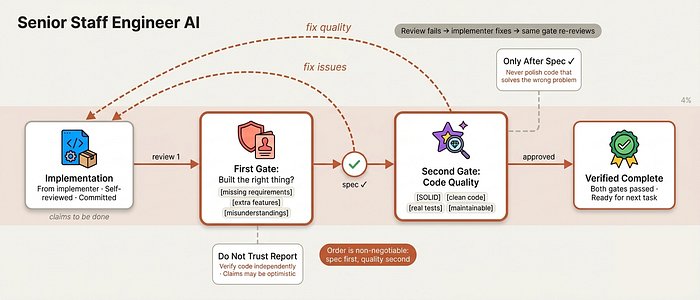
整个系统像一家真正的工程公司,职责清晰分工:
- 架构师(Architect):逐个提问、探索方案、产出设计文档——不写一行代码,直到人类批准
- 技术主管(Tech Lead):把设计拆成 2-5 分钟的任务,指定文件路径和完整代码
- 执行经理(Manager):为每个任务启动独立 Sub-Agent,卡住的上报,坏的中止重派
- 质量门禁(Quality Gates):两道独立审查
- TDD 铁律:先写测试再写代码,毫无例外
所有代码已开源:GitHub - FareedKhan-dev/claude-code-staff-engineer
2. 团队代码库:三层架构
作为一个需要协作的 Agent 团队,不能像单兵作战那样”让 Claude 自己摸索”。系统需要一个类似人类工程团队的结构化代码库:
senior_staff_engineer/
├── agents/ # 团队花名册——定义谁做什么
├── commands/ # 自定义 CLI 命令
├── hooks/ # 管理层——控制信息流和初始化
├── skills/ # 员工手册——流程和标准
agents/ 是团队目录,定义每个 Agent 的角色和职责。skills/ 是员工手册,包含每个成员必须遵守的流程。hooks/ 是管理层,确保每次会话开始时所有 Agent 都对齐。
2.1 Hooks:管理层基础设施
在真实公司里,每天开工前办公室已经开好门、咖啡机在运行、日历已同步——没人会注意到这些基础设施,直到它们出问题。
在 Claude Code 里,hooks 就是这个管理层。
配置很简单:每次会话启动时,运行初始化脚本。
{
"hooks": {
"SessionStart": [
{
"matcher": "startup|clear|compact",
"hooks": [
{
"type": "command",
"command": "\"${PROJECT_ROOT_DIR}/hooks/run-hook.cmd\" session-start",
"async": false
}
]
}
]
}
}
async: false 是关键——好比”早会没开完,谁都不准打开电脑”。因为对 AI Agent 来说,每次会话都是 D-Day,它没有昨天会话的记忆,每次都需要重新入职。
脚本在启动时将核心技能文件注入 Agent 上下文,相当于入职培训手册。它还兼容 Claude Code、Cursor 和 Copilot CLI 三种平台——跨平台思维正是 Staff Engineer 该有的基础设施设计。
2.2 员工手册:1% 规则
SKILL.md 是整个系统最重要的文件,开篇第一条规则是所有行为的基石:
如果你觉得有 1% 的可能性某个技能适用于当前任务,你必须调用它。这不是建议。不是可选项。你不能用任何理由绕过去。
这就是 1% 规则。没有它,Agent 会把技能当建议——任务”看起来简单”就跳过头脑风暴,”只是改个配置”就跳过 TDD,”就两行代码”就跳过审查。
每位 Senior 工程师都见过团队如何通过这些”小理由”逐渐放弃流程,结果总是同样的:质量下降、Bug 上线、谁都不知道发生了什么。
但 Sub-Agent 有一个逃生阀:如果它是被主 Agent 派来执行特定任务的,它不需要走完整的技能发现流程——相当于告诉合同工”你不需要参加全员大会,做你被雇来干的事就行”。
3. 头脑风暴与设计:写代码前的硬门禁
在 Amazon,写产品之前先写新闻稿。在 Basecamp,先写 pitch 文档。在 Google,设计文档要通过三个级别的审查才允许写一行代码。
共同点是什么?先想,再造。
在 Fareed 的系统中,头脑风暴技能开篇就是一道硬门禁(Hard Gate):
在呈现设计方案并获得用户批准之前,不得调用任何实现技能、不得写任何代码、不得搭建任何项目。这适用于每一个项目,无论你觉得它多简单。
最危险的理由是”这个太简单了,不需要设计”。但经验表明——”简单”的配置修改影响了三个服务;”快速”的工具函数需要处理七个没人提到的边界条件;”简单”的 Todo 应用最后需要离线同步、冲突解决和多用户支持。
简单项目恰恰是未检验假设造成浪费最多的地方。
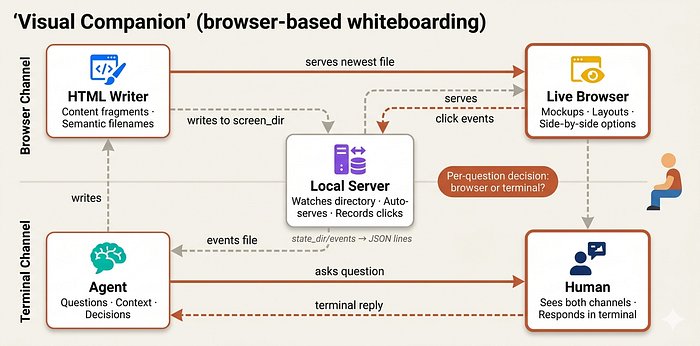
3.1 视觉白板辅助
在设计环节,系统还提供一个白板工具——当 Agent 觉得某些设计问题用视觉呈现比文字描述更清晰时,它会主动启动一个本地服务器,在浏览器中渲染设计方案的交互式线框图。
这不是被动的工具——Agent 自己判断哪些问题适合视觉呈现,然后主动启动。就像在会议上画白板的资深工程师。
3.2 技能发现流程
系统定义了一套完整的技能发现流程:收到任务 → 检查是否有技能适用 → 调用技能 → 声明正在使用的技能 → 遵循技能清单 → 响应。
最难的部分不是定义流程,而是拦截 Agent(和人)的自我合理化倾向。系统内置了一张红牌表:
| 想法 | 现实 |
|---|---|
| “这只是一个简单问题” | 问题就是任务。先查技能。 |
| “我需要更多上下文” | 技能检查必须在提澄清问题之前。 |
| “我对这个技能很熟悉” | 技能会演进。读当前版本。 |
| “用技能有点小题大做了” | 简单的事情也会变复杂。 |
| “我觉得这样做很高效” | 无纪律的行动就是浪费时间。 |
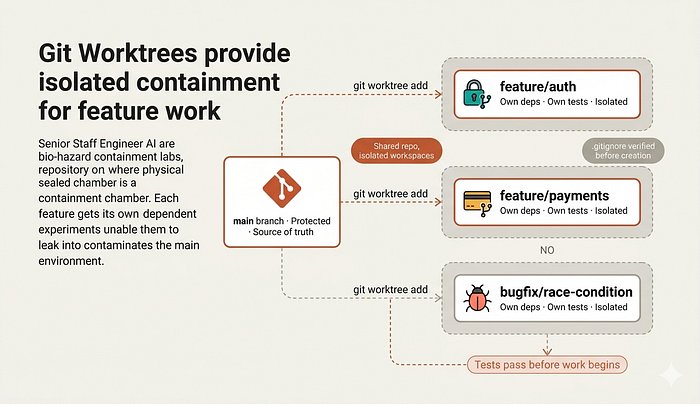
4. 执行引擎:Sub-Agent 驱动的开发
设计通过后,执行经理登场。它的工作方式是这样的:
- 为每个任务启动一个独立的 Sub-Agent,上下文完全隔离
- 卡住的 Agent 自动上报
- 执行质量差的 Agent 被终止并重新派发
- 每个 Sub-Agent 有清晰的职责边界,不会相互干扰
4.1 Plan Review:计划审查关卡
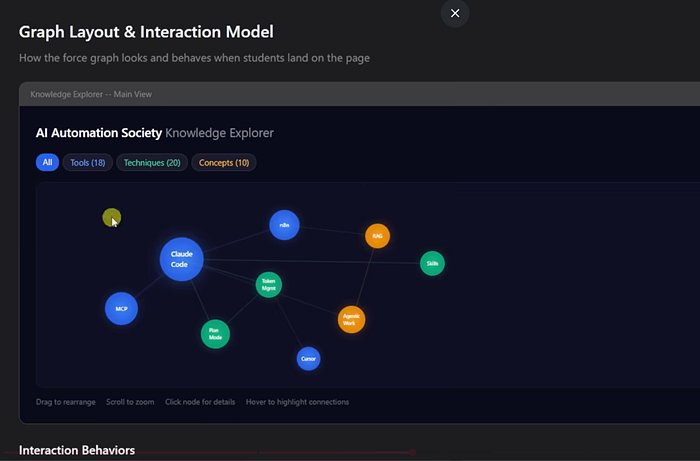
在执行之前,所有任务计划要经过一个独立的 Sub-Agent 审查:
- Spec Review:检查计划是否完整覆盖了设计文档的要求
- Scope Creep 检查:确保计划没有超出设计范围
- 任务粒度验证:每个任务必须在 2-5 分钟内完成
这个审查者是一个独立的 Sub-Agent,被专门创建来”找茬”的。它的工作就是挑毛病——如果找不出问题,说明审查不够仔细。
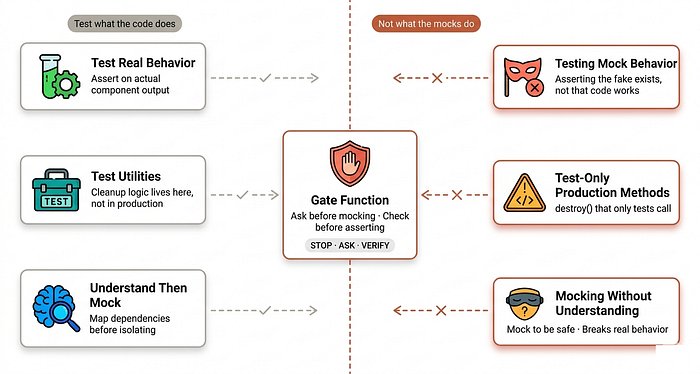
4.2 质量门禁:两道审查
每个任务完成之后,要经过两道独立审查:
- Spec Compliance Review(做对的事?)— 代码是否符合设计规范
- Code Quality Review(做得好吗?)— 代码质量是否达标
验证门禁更进一步:任何完成声明都必须附带新的终端输出作为证据。只有纯文本的”我完成了”不算数。
5. TDD 铁律与系统化调试
5.1 先写测试,再写代码
Fareed 的系统把 TDD 定为不可撼动的铁律:
先写代码再写测试?删除代码。重来。没有例外:
- 不能”留着当参考”
- 不能在写测试时”顺便适配”
- 不能”看一眼”
- 删除就是删除
系统还为 TDD 定义了一系列反模式——那些 Agent 试图走捷径的方式:
- Test-Last Laziness:写完代码再补测试 = 测试覆盖的是写好的代码,不是需求
- Happy-Path Only:只测正常路径,异常路径全部忽略
- Assertion Minimalism:断言数量最少化,通过的测试没有价值
- Mock Everything:过度 Mock 让测试与具体实现耦合
每种反模式都有明确的定义和对应的修正策略。
5.2 四阶段调试法
Bug 修复不是随意开始的。系统有一套四阶段取证流程:
- 理解 Bug — 生成精确的复现步骤
- 定位根因 — 用日志、断点、二分法找到根本原因
- 修复 — 只改最少量的代码
- 验证 — 确认修复有效且没有回归
根因追踪要求五层深度——不是问”哪行代码错了”,而是追问”为什么那行代码会存在”、”为什么测试没发现”、”为什么 review 没发现”、”是什么流程漏洞允许它上线”。
6. 写技能 = 对流程文档做 TDD
这个系统最反直觉的设计是:写 SKILL.md 的过程本身就是 TDD。
写测试用例(Agent 压力测试)→ 看它们失败(基线行为)
→ 写技能文档 → 看测试通过(Agent 遵守流程)→ 重构(修补漏洞)
核心原则:如果你没有见过 Agent 在没有技能时的失败行为,你就不知道技能该教什么。
大多数团队把流程文档写出来、发布到 Confluence,就假设它有效。但 Fareed 的系统把文档当代码——你不会把函数不经测试就上线,为什么流程文档要例外?
不同的技能需要不同的测试类型:
- 纪律性技能(必须遵守的规则)→ 压力测试 + 组合压力测试
- 技术性技能(如何操作)→ 应用场景测试
- 参考性技能(API 文档)→ 检索测试
7. 真实效果:测试一个完整项目
Fareed 用一个真实项目验证了系统效果:从 YouTube 转录集合构建一个交互式技能关联可视化图谱。
系统做的第一件事完全不像在”做项目”——它探索。调用头脑风暴技能 → 派 Sub-Agent 扫描项目结构 → 阅读所有文档 → 不形成任何意见,只是安静地了解。
然后它创建一个完整的头脑风暴清单,一步一步执行。它甚至主动提供了一个视觉白板——在问第一个问题之前,先启动了本地服务端,让设计问题可以在浏览器中可视化的呈现和讨论。
提问方式是一个接一个的苏格拉底式追问,而不是一次性抛出一堆问题。每一次追问都基于前一次的答案——这才能发掘批量提问永远发现不了的细节:比如”视觉探索应该是主要访问模式”这个需求,会改变整个架构。
一旦收集完需求,它不是在代码编辑器里写,而是在白板浏览器中渲染三种不同方案的交互式线框图,标注优劣,等人类选择。
从开始到第一行生产代码产生前,房间里的环节都是纯思考。没有实现。没有搭建项目结构。没有一个 Agent 说”让我先搭个架子”。
8. 如何进一步改进
作者在文末留下了一个路线图,指向了下一个阶段的方向:
- 跨会话记忆:每次会话都是 D-Day,一个持久的记忆层让 Agent 可以积累机构知识
- 模型路由:根据任务复杂度自动选择不同成本的模型
- Agent 间通信:让并行工作的 Sub-Agent 能互相发现”我找到了一个共享工具”
- 技能回归测试:CI 流程每晚运行压力场景,发现 Agent 开始绕过流程时自动报警
- 人工反馈闭环:当人类驳回一个决定时,反馈信号加固被违反的规则
这些方向让这个系统从一个”AI 开发辅助”向”AI 工程组织”演进——不再只是一个更聪明的代码助手,而是一个拥有流程、纪律、学习能力的数字工程团队。
9. 总结
FareedKhan 的这个项目展示了一个重要趋势:未来 AI Agent 开发的瓶颈不是模型能力,而是工程纪律。
当多个 Agent 协作时,”更多的 Agent = 更多的混乱”这条规律和人类世界如出一辙。唯一能打破它的是——比人类更严格的流程定义、更彻底的规则执行、更不留情面的质量审查。
这个系统的设计哲学值得每个做 Agent 开发的团队学习:先定义流程,再写代码;先设置门禁,再开放权限;先测试技能,再部署执行。
它的价值不在于自动化了多少工作,而在于把软件开发中最难复制的东西——工程文化的流程纪律——变成了可编程、可复用的资产。