Claude 认证架构师 CCA 考试完全指南:通过技巧、5 大领域与 4 周备考计划
1. 为什么 CCA 认证现在很重要
2026 年 3 月 12 日,Anthropic 正式推出了 Claude 认证架构师(CCA)基础考试。这是 AI 行业第一个真正测试你是否能构建生产级 Claude 系统的专业认证——不是能不能写聪明的 prompt,不是有没有看过教程,而是能不能架构真实的生产系统。
Anthropic 为这个认证投入了 1 亿美元的 Claude Partner Network。看看合作伙伴的承诺:Accenture 培训了 30,000 名专业人员并成立了专属 Anthropic 业务组;Cognizant 给了 350,000 名员工 Claude 访问权限;Deloitte 将 470,000 人部署到了平台上。这些不是试点项目,是以数十万人计的人力转型。
这对你的意义:所有这些组织都需要能专业架构 Claude 系统的人。CCA 认证给了招聘经理一个标准化的信号——在一个目前完全没有标准化信号的市场上。你现在拿到 CCA 徽章和两年后人手一张时的价值完全不同。
2. 考试格式
| 项目 | 数据 |
|---|---|
| 题目数 | 60 道选择题 |
| 时间 | 120 分钟 |
| 通过分 | 720 / 1000 |
| 费用 | $99 |
| 监考 | 是 |
| 可用资源 | 无(不能查文档、不能问 Claude) |
每道题约 2 分钟。题目不是词汇题——每道题描述一个生产场景(150-200 字),然后让你选最佳架构决策。你需要快速阅读、更快地模式匹配。高分考生报告说他们的速度来自于瞬间识别陷阱模式,而非逐字阅读。
考试从 6 个生产场景中随机抽取 4 个,所以你不能跳过任何一个场景。
3. 五大能力领域
3.1 领域一:Agent 架构与编排(27%)
这是重中之重,超过四分之一的考试内容。核心知识点:
多 Agent 模式: 协调者-子 Agent 模式(coordinator 委托任务给 specialized subagents 并综合结果)和 hub-and-spoke(独立并行任务)。必须知道何时适用、何时失败。
子 Agent 上下文隔离(最常考的陷阱): 子 Agent 不会自动继承上下文。当 coordinator 生成子 Agent 时,子 Agent 从空白上下文开始。你必须显式传递所需的一切。这听起来很基础,但考试会在场景中测试——考生往往假设上下文会在 Agent 之间自然流动。
会话状态管理: 如何在 Agentic 循环中维护对话上下文。状态存在哪里?如何防止上下文无限增长?
任务分解: 将复杂请求拆分为离散子任务。考试测试你能否识别正确的粒度。
升级逻辑: Agent 何时以及如何将问题转交给人或更强大的系统。考试奖励确定性升级规则,而非模型驱动的升级。
💡 考试技巧: 领域一最常见的陷阱是「超级 Agent」反模式——一个 Agent 有 15+ 个工具,而不是 3-4 个专门子 Agent 各带 4-5 个工具。当答案选项把一切塞进一个强大的 Agent 中时,基本可以排除。
3.2 领域二:Claude Code 配置与工作流(20%)
CLAUDE.md 层级: 项目级(.claude/CLAUDE.md,版本控制共享)vs 用户级(~/.claude/CLAUDE.md,个人本地)。项目级是「技术主管」文件,设定团队标准;用户级是你的个人定制。
自定义斜杠命令和技能: 如何创建可复用的 markdown 技能。需要知道结构,不只是知道它们存在。
Plan 模式 vs 直接执行: Plan 模式适合复杂多步骤任务;直接执行适合定义明确、风险较低的任务。考试测试你判断哪种模式合适的决策能力。
CI/CD 集成: -p(或 --print)标志用于非交互式管线。在 CI/CD 中忘记 -p 标志是一个被大量测试的反模式。--bare 标志用于可重现行为。--output-format json 用于结构化 JSON 输出。
💡 考试技巧: CI/CD 题目几乎总有一个陷阱答案是「在 CI/CD 中交互式运行 Claude Code」或「未使用 -p 标志」。
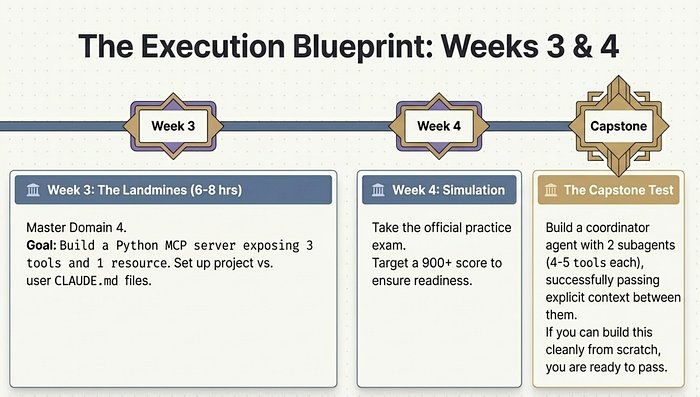
3.3 领域三:Prompt 工程与结构化输出(20%)
JSON Schema 强制: 使用 tool_choice 搭配输入 schema 来强制结构化输出。不是让 Claude 在 system prompt 里「输出 JSON」,而是用 API 的工具机制程序化地约束输出格式。
结构化输出 API: client.messages.parse() 与 Pydantic 模型(beta 功能)。
验证-重试循环: 检查输出是否符合 schema。如果失败,将错误发回 Claude 并指示修复。tool_use stop reason 是你检查和验证的信号。
核心反模式: 仅靠 prompt 来保证 JSON 合规。”请在 system prompt 中添加更详细的格式指导”作为解决方案几乎肯定是错的。正确答案是 tool_choice、结构化输出 API 和验证-重试循环。
3.4 领域四:工具设计与 MCP 集成(18%)
社区反馈一致认为这是考生意外失分最多的领域。
MCP 原语及使用场景:
- 工具(Tools): 模型可调用的可执行函数。用于操作:查询数据库、调用 API、写入文件。
- 资源(Resources): 供 prompt 或 RAG 管线摄取的数据。用于只读上下文:文档、schema、知识库。
- 提示(Prompts): 预定义模板或工作流。用于可复用的指令模式。
工具-资源边界是最难的判断。问自己:Claude 是需要调用来执行操作,还是只需要数据作为上下文?操作=工具,上下文=资源。
工具描述即路由: 你写的工具描述是 Claude 决定调用哪个工具的主要机制。Agent 名称对路由不重要。工具名不如描述重要。把工具描述写成给从未见过你代码库的开发者的文档。
4-5 工具规则: Anthropic 官方指南是每个 Agent 4-5 个专注工具。当 Agent 有 18 个工具时,选择可靠性显著下降。多余的工具分发给专门的子 Agent。
3.5 领域五:上下文管理与可靠性(15%)
权重最小,但交叉影响了所有场景。
Lost in the Middle 效应: Claude 和所有基于 transformer 的 LLM 对上下文窗口开头和结尾的信息关注更多。中间的内容受到较少的注意力。关键信息放在开头或结尾。
长会话中的上下文退化: 随着对话增长,早期上下文变得不可靠。缓解方案:结构化摘要、周期性重申关键事实。
升级设计: Agent 应何时停止尝试并转交。模式:确定性规则触发升级,而不是模型自我评估。
代币经济学:
- Prompt Caching: 节省高达 90% 成本,实时延迟。适用于重复的 system prompt、策略文档、few-shot 示例。
- Message Batches API: 节省 50% 成本,延迟最多 24 小时(大多 1 小时内)。适用于夜间审计、批量处理、离线工作负载。
- 实时 API: 标准定价,实时延迟。适用面向用户、需阻塞的工作流。
💡 考试技巧: 成本优化问题中,如果有人正在等待响应,答案绝不可能是 Batches API。正确答案是 Prompt Caching。
4. 六个生产场景
考试从以下 6 个场景中随机抽 4 个:
- 客户支持解析 Agent: 处理退货、账单纠纷等。测试升级逻辑和合规约束。最大陷阱:用 Claude 的自报置信度来决定是否升级。
- Claude Code 代码生成: 配置大代码库导航和代码生成。测试上下文退化意识和 Plan 模式 vs 直接执行。
- 多 Agent 研究系统: coordinator 将研究任务分派给专门子 Agent。陷阱:「超级 Agent」反模式。
- 开发者生产力工具: 自定义斜杠命令和 CLAUDE.md 配置。测试 Plan 模式 vs 直接执行。
- Claude Code 用于 CI/CD: 自动化代码审查、测试生成和 PR 反馈。必须掌握
-p标志。 - 结构化数据提取: 从非结构化文档中提取结构化数据。陷阱:纯 prompt 方式。
5. 核心心智模型
考试通过的考生和失败的考生之间,差距来自于这五个原则:
心智模型 1:程序化强制优于基于 prompt 的指导
每次都是。业务规则、JSON 合规、路由决策——不要让 Claude 在 prompt 里遵循规则。在代码中强制。Prompt 是指导,代码是法律。
心智模型 2:子 Agent 不继承上下文
当 coordinator 生成子 Agent 时,子 Agent 从头开始。你必须显式传递所需上下文。这是整个考试中最常测试的概念之一——因为它反直觉。
心智模型 3:工具描述驱动路由
Claude 不是根据 Agent 名称或工具名称选择工具——它读工具描述。描述写得差 = 调错工具。写得具体、精确、无歧义。
心智模型 4:Lost in the Middle 是真实存在的
关键信息放在上下文的开头或结尾。中间的内容被稀释。这影响了每个涉及长上下文的场景。
心智模型 5:API 要与延迟需求匹配
Batches API = 后台作业。实时 API = 用户面向的工作流。Prompt Caching = 重复上下文的成本优化。问第一个问题:有人在等这个响应吗?
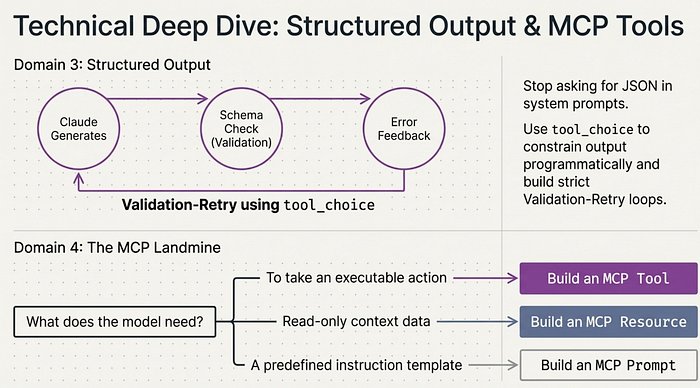
6. 反模式目录(必背)
| 领域 | 反模式 | 正确模式 |
|---|---|---|
| Agent 架构 | 1 个 Agent 15+ 个工具 | 4-5 个专注工具/Agent,多余的给子 Agent |
| Agent 架构 | 用自报置信度做路由决策 | 确定性业务规则(金额、等级、类型) |
| Agent 架构 | 假设子 Agent 继承上下文 | 显式传递所需上下文 |
| Claude Code | CI/CD 中没加 -p 标志 | 使用 -p + –bare 非交互模式 |
| Claude Code | 用户偏好放项目 CLAUDE.md | 放 ~/.claude/CLAUDE.md |
| Claude Code | 复杂修改用直接执行 | 用 Plan 模式 |
| Prompt 工程 | 仅靠 prompt 强制 JSON | tool_choice + schema + 验证重试 |
| 工具设计 | 只读数据暴露为工具 | 用 MCP Resources |
| 工具设计 | 模糊的工具描述 | 具体精确的描述 |
| 上下文管理 | 实时场景用 Batches API | 实时场景用实时 API |
| 上下文管理 | 原始对话记录作为升级交接 | 结构化 JSON 摘要 |
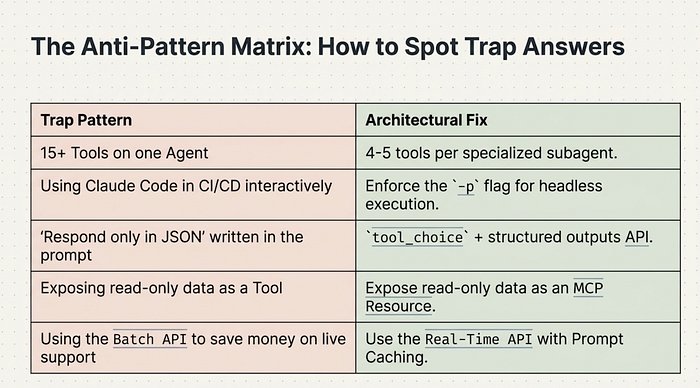
7. 四周备考计划

第 1 周:基础与心智模型
- 学习 AI Fluency 框架(委托、描述、辨别、勤勉)
- 掌握核心词汇:agentic loop, stop reason, tool_choice, context forking
- 目标: 不查资料能定义上述所有术语
第 2 周:核心技能(最高投入周)
- 「使用 Claude API 构建」课程(8-10 小时)
- 从头构建验证-重试循环
- 用 tool_choice + JSON schema 练习结构化输出
- 目标: 有可运行的验证-重试循环、tool_choice 强制输出、带 3-4 个工具的 Agent
第 3 周:进阶主题
- 用 Python 构建 MCP 服务器,暴露 3 个工具 + 1 个资源
- 在真实项目中配置 CLAUDE.md
- 在 CI/CD 管线中用 -p 标志运行 Claude Code
- 目标: 有可工作的 MCP 服务器、配置好的 CLAUDE.md、成功的 headless Claude Code 运行
第 4 周:模拟考试与反模式
- 做官方模拟考试(满分 1000,目标 900+)
- 按领域分类错题
- 构建收官项目:coordinator + 2 个子 Agent,各带 4-5 个工具,显式传递上下文
- 过一遍反模式目录
8. 总结
CCA 考试不是「看个教程就能过」的认证。它在 Agent 架构、MCP 工具集成和多 Agent 编排上的深度相当扎实。模拟题中 72%(43/60)就能通过,但建议冲 83%(50/60)再报名。
最重要的几条原则:
- 子 Agent 不继承上下文——这是考试第一陷阱
- 4-5 个工具/Agent——超了就要拆子 Agent
- 用代码强制,不用 prompt 建议——关乎安全问题
- 工具 vs 资源边界——失分最多的领域
-p标志不能忘——CI/CD 场景的必杀技
如果你已经在用 Claude API 和 Claude Code 构建系统,大部分材料你应该已经熟悉。考试测试的是你能否在时间压力下精确地选出正确答案。用 4 周计划准备,注意反模式,到 Anthropic Academy 刷免费课程然后预约考试。